Cloud Availability
Cloud Computing has become very widespread with startups as well as divisions of banks, pharmaceuticals companies and other large corporations using them for computing and storage.
Amazon Web Services has led the pack with it's innovation and execution, with services such S3 storage service, EC2 compute cloud, and SimpleDB online database.
Many options exist today for cloud services, for hosting, storage and application hosting. Some examples are below:
[A good compilation of cloud computing is here, with a nice list of providers here. Also worth checking out is this post.]
The high availability of these cloud services becomes more important with some of these companies relying on these services for their critical infrastructure. Recent outages of Amazon S3 (here and here) have raised some important questions such as this - S3 Outage Highlights Fragility of Web Services and this.
[A simple search on search.twitter.com can tell you things that you won't find on web pages. Check it out with this search, this and this.]
There has been some discussion on the high availability of cloud services and some possible solutions. For example the following posts - "Strategy: Front S3 with a Caching Proxy" and "Responding to Amazon's S3 outage".
Here I am writing of some thoughts on how these cloud services can be made highly available, by following the traditional path of redundancy.
Cost Impact
Any of the hot-standby configurations would have cost impact - adding any extra layer of high-availability immediately adds to the cost, at least doubling the cost of the infrastructure. This cost increase can be reduced by making only those parts of your infrastructure highly-available that affect your business the most. It depends on how much business impact does a downtime cause, and therefore how much money can be spent on the infrastructure.
One of the ways to make the configurations more cost effective is to make them active-active configuration also called a load balanced configuration - these configurations would make use of all the allocated resources and would send traffic to both the servers. This configuration is much more difficult to design - for example if you put the hot-standby-storage in active-active configuration then every "write" (DB insert) must go to both the storage-servers, writes (DB insert) must not complete on any replicas (also called mirrored write consistency).
Cloud Computing becoming mainstream
As cloud computing becomes more mainstream - larger web companies may start using these services, they may put a part of their infrastructure on a compute cloud. For example, I can imagine a cloud dedicated for "data mining" being used by several companies, these may have servers with large HDDs and memory and may specialize in cluster software such as Hadoop.
Lastly I would like to cover my favorite topic -why would I still use services that cost more for my core services instead of using cloud computing?
Amazon Web Services has led the pack with it's innovation and execution, with services such S3 storage service, EC2 compute cloud, and SimpleDB online database.
Many options exist today for cloud services, for hosting, storage and application hosting. Some examples are below:
| Hosting | Storage | Applications |
| Amazon EC2 | Amazon S3 | opSource |
| MOSSO | Nirvanix | Google Apps |
| GoGrid | Microsoft Mesh | Salesforce.com |
| AppNexus | EMC Mozy | |
| Google AppEngine | MOSSO CloudFS | |
| flexiscale |
The high availability of these cloud services becomes more important with some of these companies relying on these services for their critical infrastructure. Recent outages of Amazon S3 (here and here) have raised some important questions such as this - S3 Outage Highlights Fragility of Web Services and this.
[A simple search on search.twitter.com can tell you things that you won't find on web pages. Check it out with this search, this and this.]
There has been some discussion on the high availability of cloud services and some possible solutions. For example the following posts - "Strategy: Front S3 with a Caching Proxy" and "Responding to Amazon's S3 outage".
Here I am writing of some thoughts on how these cloud services can be made highly available, by following the traditional path of redundancy.
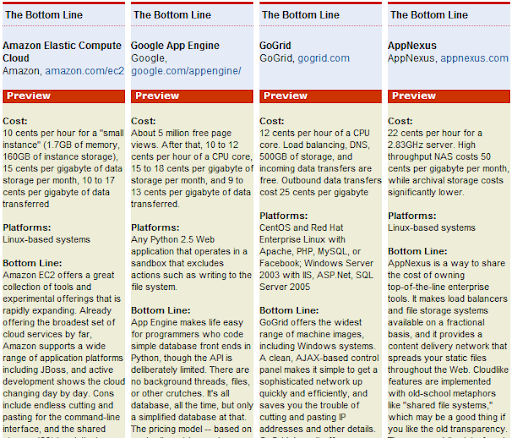
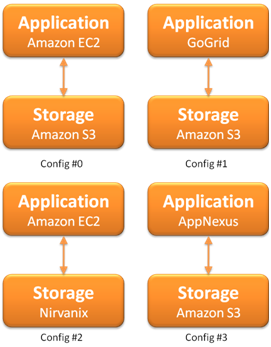 | The traditional way of using AWS S3 is to use it with AWS EC2 (config #0). Configurations such as on the left can be made to make your computing and storage not dependent on the same service provider. Config #1, config #2 and config #3 mix and match some of the more flexible computing services with storage services. In theory the compute and the storage can be separately replaced by a colo service. |
| The configurations on the right are examples of providing high availability by making a "hot-standby". Config #4 makes the storage service hot-standby and config #5 separates the web-service layer from the application layer, and makes the whole application+storage layer as hot-standby. A hot-standby requires three things to be configured - rsync, monitoring and switchover. rsync needs to be configured between hot-standby servers, to make sure that most of the application and data components are up to date on the online-server. So for example in config #4 one has to rsync 'Amazon S3' to 'Nirvanix' - that's pretty easy to setup. In fact, if we add more automation, we can "turn-off" a standby server after making sure that the data-source is synced up. Though that assumes that the server provisioning time is an acceptable downtime, i.e. the RTO (Recovery time objective) is within acceptable limits. |   |
| This also requires that you are monitoring each of the web services. One might have to do service-heartbeating - this has to be designed for the application, this has to be designed differently for monitoring Tomcat, MySQL, Apache or their sub-components. In theory it would be nice if a cloud computing service would export APIs, for example an API for http://status.aws.amazon.com/ , http://status.mosso.com/ or http://heartbeat.skype.com/. However, most of the times the status page is updated much later after the service goes down. So, that wouldn't help much. | Switchover from the online-server/service to the hot-standby would probably have to be done by hand. This requires a handshake with the upper layer so that requests stop and start going to the new service when you trigger the switchover. This might become interesting with stateful-services and also where you cannot drop any packets, so quiscing may have to be done for the requests before the switchover takes place. |
 Above are two configurations of multi-tiered web-services, where each service is built on a different cloud service. This is a theoretical configuration, since I don't know of many good cloud services, there are only a few. But this may represent a possible future, where the space becomes fragmented, with many service providers. | 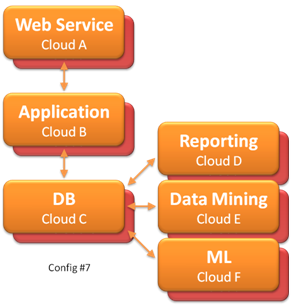 Config #7 is config #6 with hot-standby for each of the service layers. Again this is a theoretical configuration. |
Cost Impact
Any of the hot-standby configurations would have cost impact - adding any extra layer of high-availability immediately adds to the cost, at least doubling the cost of the infrastructure. This cost increase can be reduced by making only those parts of your infrastructure highly-available that affect your business the most. It depends on how much business impact does a downtime cause, and therefore how much money can be spent on the infrastructure.
One of the ways to make the configurations more cost effective is to make them active-active configuration also called a load balanced configuration - these configurations would make use of all the allocated resources and would send traffic to both the servers. This configuration is much more difficult to design - for example if you put the hot-standby-storage in active-active configuration then every "write" (DB insert) must go to both the storage-servers, writes (DB insert) must not complete on any replicas (also called mirrored write consistency).
Cloud Computing becoming mainstream
As cloud computing becomes more mainstream - larger web companies may start using these services, they may put a part of their infrastructure on a compute cloud. For example, I can imagine a cloud dedicated for "data mining" being used by several companies, these may have servers with large HDDs and memory and may specialize in cluster software such as Hadoop.
Lastly I would like to cover my favorite topic -why would I still use services that cost more for my core services instead of using cloud computing?
- The most important reason would be 24x7 support. Hosting providers such as servepath and rackspace provide support. When I give a call to the support at 2PM India time, they have a support guy picking up my calls – that’s a great thing. Believe me 24x7 support is a very difficult thing to do.
- These hosting providers give me more configurability for RAM/disk/CPU
- I can have more control over the network and storage topology of my infrastructure
- Point #2 above can give me consistent throughput and latency for I/O access, and network access
- These services give me better SLAs
- Security
posted by Unknown, permalink
14 comments
![]()
![]()