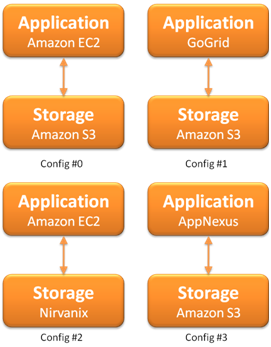
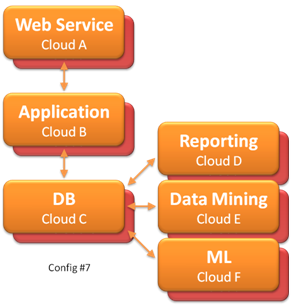
Cloud Computing: How important is "data locality" from a costing perspective?
Nicholas Carr wrote an excellent article about cloud computing "The new economics of computing".
One thing missed in the "NYT TIFF to PDF conversion computational task" is the mention of data transfer cost of uploading 4TB TIFF images into S3.
Doing some simple computations – Amazon would charge about $409.60 for uploading 4TB data into S3, and would charge an additional $261.12 for downloading the processed PDF files, which were 1.5TB in size. That is about $670.72. In addition there will be bandwidth charges of this 5.5TB data transfer from the NYT datacenter, 4TB out and 1.5TB in, I am sure that will be of the order of $400-$600. That could take the data transfer costs to $1000-$1200 range.
In addition to that – consider the amount of time it would take to transfer such a data. At 10Mbps, it would take 53.4 days to transfer this data.
Using Hadoop on EC2 is definitely a great idea, and is very helpful, however the locality of data also matters a lot. Moving data, in my opinion costs a lot, and sometimes undermines the computational costs ($240 here).
Let me know your thoughts.
"In late 2007, the New York Times faced a challenge. It wanted to make available over the web its entire archive of articles, 11 million in all, dating back to 1851. It had already scanned all the articles, producing a huge, four-terabyte pile of images in TIFF format. But because TIFFs are poorly suited to online distribution, and because a single article often comprised many TIFFs, the Times needed to translate that four-terabyte pile of TIFFs into more web-friendly PDF files.
Working alone, he uploaded the four terabytes of TIFF data into Amazon's Simple Storage Service (S3) utility, and he hacked together some code for EC2 that would, as he later described in a blog post, "pull all the parts that make up an article out of S3, generate a PDF from them and store the PDF back in S3." He then rented 100 virtual computers through EC2 and ran the data through them. In less than 24 hours, he had his 11 million PDFs, all stored neatly in S3 and ready to be served up to visitors to the Times site.
The total cost for the computing job? Gottfrid told me that the entire EC2 bill came to $240. (That's 10 cents per computer-hour times 100 computers times 24 hours; there were no bandwidth charges since all the data transfers took place within Amazon's system - from S3 to EC2 and back.)"
Working alone, he uploaded the four terabytes of TIFF data into Amazon's Simple Storage Service (S3) utility, and he hacked together some code for EC2 that would, as he later described in a blog post, "pull all the parts that make up an article out of S3, generate a PDF from them and store the PDF back in S3." He then rented 100 virtual computers through EC2 and ran the data through them. In less than 24 hours, he had his 11 million PDFs, all stored neatly in S3 and ready to be served up to visitors to the Times site.
The total cost for the computing job? Gottfrid told me that the entire EC2 bill came to $240. (That's 10 cents per computer-hour times 100 computers times 24 hours; there were no bandwidth charges since all the data transfers took place within Amazon's system - from S3 to EC2 and back.)"
One thing missed in the "NYT TIFF to PDF conversion computational task" is the mention of data transfer cost of uploading 4TB TIFF images into S3.
Doing some simple computations – Amazon would charge about $409.60 for uploading 4TB data into S3, and would charge an additional $261.12 for downloading the processed PDF files, which were 1.5TB in size. That is about $670.72. In addition there will be bandwidth charges of this 5.5TB data transfer from the NYT datacenter, 4TB out and 1.5TB in, I am sure that will be of the order of $400-$600. That could take the data transfer costs to $1000-$1200 range.
In addition to that – consider the amount of time it would take to transfer such a data. At 10Mbps, it would take 53.4 days to transfer this data.
Using Hadoop on EC2 is definitely a great idea, and is very helpful, however the locality of data also matters a lot. Moving data, in my opinion costs a lot, and sometimes undermines the computational costs ($240 here).
Let me know your thoughts.
Labels: amazon, cloud, computing, costing, data, ec2, locality, s3
posted by Unknown, permalink
4 comments
![]()
![]()